https://zhuanlan.zhihu.com/p/645308698
Introduction
Large Language Models (以下简称LLMs) 近一年凭借其“大力出奇迹”的方式达到了各大NLP任务的指标新高。特别是在GPT-3之后, NLP领域进入了由 pretrain + prompt 的范式代替 pretrain + fine-tuning 的Bert范式的时代. 但真正引起整个AI领域注视的, 还是2022年底ChatGPT的面世, 让从事AI相关的所有人员甚至是世界的普通群众都感受到了其惊人的智能. 目前, 国内已进入”百模大战”, 不管是大厂异或是创业公司都在争先恐后地招兵买马, 扩充算力, 希望能实现中国版的ChatGPT, 抢得头筹。然而, 复现其智能只是第一步, 后续的模型落地部署才是考验一个公司产品是否可以实现营利的关键。从目前ChatGPT按token收费的情况来看, 每token推理成本的摊销将会决定产品定价和背后的营利空间. 如果按目前收费单位为: xx美分/1k token, 推理成本可以简单转化为模型每1k token的平均推理时间 x 功耗 x 电费计价(当然, 这里面没有统计GPU的购买成本/ 人力成本等). 尤其对于像国内有些公司是希望借助GPT的能力来优化自身产品以实现营利(我个人将其理解为”隐式收费”), 那其GPT的运营成本将更为敏感。
身为从事模型小型化的技术人员, 我们关注的是模型的平均推理时间和功耗, 平均推理时间可以用latency 或 throughput 来衡量, 而功耗则可以用参考生成token过程中所用到GPU的功耗(因为如果是用TP/PP等方法就会引入多个GPU)来近似. 这两个指标都与模型参数量紧密相关, 特别是LLMs的参数量巨大, 导致部署消耗GPU量大(而且甚至会引起旧GPU, 如: 2080ti等消费级卡直接下线离场)及GPU的IO时间长(memory write/read 的cycles是要远大于 operations cycles, 印象中是百倍), 故在部署过程中如何使得模型变得更小更轻, 且保持智能尽可能不下降就成了一个重要的研究话题。而今天的主题: 量化(Quantization), 可以很好地通过将float模型表征为低位宽模型实现减小模型存储空间, 加速模型推理的目标. (注: 其他的小型化技术以后有机会再介绍)
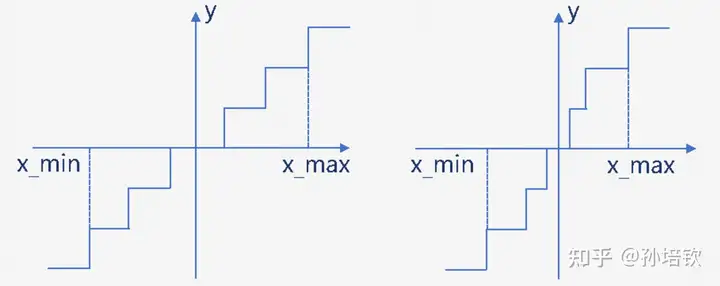
量化, 在深度学习领域中, 可以将其定义为 a technique that mapping of a k-bit integer to a float element, which saves space and speedup computation by compressing the digital representation. 量化可以按不同角度对其进行归类: 按量化执行的阶段, 可以分为训练中量化(QAT, Quantization-Aware-Training) 和 训练后量化(PTQ, Post-Training-Quantization); 按量化间隔是否等距, 可以其将分为均匀量化和非均匀量化(如下图所示). 我们在这里主要讨论PTQ, 均匀量化. 因为在LLMs背景下, QAT的研究目前仍未有机构做出相关的靠谱研究, 主要受限于QAT需要引入模拟量化的操作, 会引起显存&计算量进一步上涨以及梯度mismatch的问题, 从而增加训练成本以及影响Scaling Laws. 非均匀量化除非有特殊硬件支持, 否则在GPU上目前多数只能通过Look-Up-Table 或 移位等方式来实现, 速度和精度没法得到同时保证.
Backgrounds
首先, 我需要先介绍两个式子, 以方便我们后面的讨论. 1式中, Q(·)表示量化操作, X代表输入tensor, S即为scale, Z即为zero-point, b为量化位宽。1式称为quantization, 2式称为 de-quantization. S和Z统称为量化参数, 多数的量化算法可以理解为就是为了找到更好的S和Z使得量化模型的结果尽可能逼近原模型的结果. 另外, 目前关于LLMs模型的量化算法可以理解为仅关心Linear算子的量化, 对于其他部件(如: norm, embedding, softmax, add…)都没有进行研究. 所以, 下面的所有讨论均以Linear为核心研究对象, 所有示例结果将以LLaMA模型进行展示。
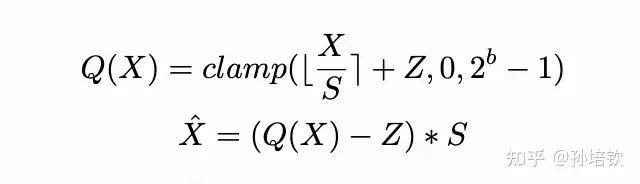
LLMs模型的推理可以大致分为两个stage: context and generation. 两个stage有其各自的鲜明的特点, 在context阶段走的是causal attention, 其行为可以类比训练的前向过程; 而generations阶段sequence length恒等于1。这就要求推理框架需要支持两套计算逻辑(在FasterTransformer中可以看出)以适配其不同的特点. 在多数情况下, context阶段是compute bound(这不一定, 需要seqlen大于计算强度), 而generation是IO bound. 很多情况下, generation较context在应用中出现频率更高, 而量化模型由于其低位宽的权重表征, 可以大大缓解IO bound现象. (当然如果在服务时使得batch化技术来加大一次推理的batch的话, 量化的效果可能会退化为节约模型存储(功耗)下降).
Methods
该章节我们将简要来介绍目前常见的应用于LLMs的量化方法, 简要讲述其方法的motivation, 具体实现方式, 优劣点。
LLM.int8()
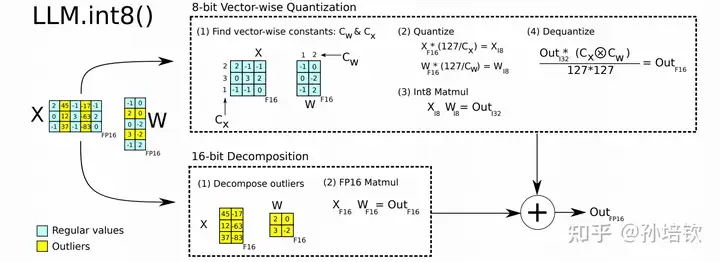
由于观察到input的outliers只会固定在几个特定的hidden-dim的特点(这点我在LLaMA模型中也观察到该现象, 且随着模型加深越发严重. 具体原因个人分析为RMSNorm引起), 且outliers占据的dims很少(不到1%). 故提出将Linear拆成两部分, 一部分为int8, 一部分为fp16, 分别计算后相加. 该方法得到广泛的应用, 有两个方面, 一个是因为被huggingface集成, 另一个是因为其几乎不掉点. 但该方法的缺点也是比较明显: 模型量化仅到8bit, 仍是4bit的2倍大; Linear的latency大幅上升, 原因在于它拆成两个matmul kernel, 而且后续为了fp16相加引入外积操作等, 即计算流程更为复杂多步.
ZeroQuant系列(v1, v2)
首次提次对采用input token-wise quantization 并结合 weight group-wise quantization; 另外设计LKD(Layerwise Knowledge Distillation, 使用随机生成的数据); 同时, 还做了一些kernel fused的工作, 实现了一个适配于int8的backend. 这系列的工作都比较像technical report, 且适用的模型尺寸比较小, 均在20B以下. 方法的scaling效果较差, 建议follow其量化粒度的设计.
SmoothQuant
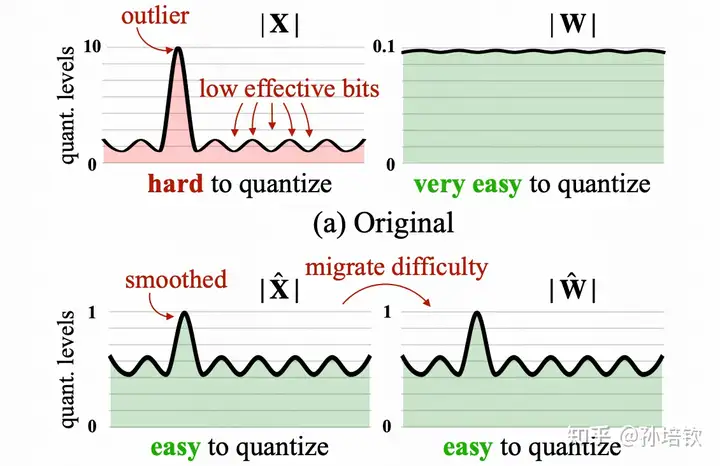
同样是为了解决input outlier的问题, 韩松团队提供将input的动态范围除上scale(该scale > 1即可以实现动态范围减小, 从而改善量化结果), 并将该scale吸到下一层的weight内, 利用weight的细粒度量化来承担该量化困难(因为input往往使用token-wise quantization, 而weight通常使用channel-wise quantization或group-wise quantization). 相较于LLM.int8(), 由于input和weight全都是int8, 并不会出现复杂的计算逻辑, 可以调用CUTLASS默认实现的int8 gemm来加速. 其缺点为: 精度没有LLM.int8()有保证, 且容易受到calibration-set的影响), 同时一旦weight精度调至4bit, 则模型精度下滑严重)
作者:孙培钦
链接:https://zhuanlan.zhihu.com/p/645308698
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
经典之作, 目前几乎是4bit/3bit方案的默认首选, 但也仅限于开源世界的娱乐可用, 离落地认定的靠谱精度还是有比较大的距离. 该方法来源于同一团队在nips22的工作(Optimal Brain Compression)延伸, 其同样将方法泛化到剪枝领域(也是大模型剪枝领域的经典, SparseGPT). 该方法的思路大致为: 利用hessian信息作为准则判定每个权重量化后对输出loss(通常定义为MSE)造成的影响, 量化影响最大的权重(即最敏感)挑选出来先进行量化, 然后对其他权重进行更新来补偿该权重量化导致的影响, 如此往复, 直至全部量化结果. 当然, 在GPTQ中作了一些简化, 比如是基于列元素进行量化循环, 来减少算法的运行时间. 该方法的优点: 首次将4bit/3bit权重量化在176B的模型上做work, 同时也提出对应的kernel(但比较糙, 优化空间大, 有不少团队做了优化). 缺点: 4bit/3bit的方案原始kernel由于有unpack操作, 导致gemv操作的计算时间低于fp16), 且精度距离落地有明显距离. 注: 从它开始, 很多人只开始研究4w16f的方案(即weight-only quantization), 因为在batch=1的gemv计算中, 只需要控制权重的读入时间即可, 且input的动态范围过大, 量化掉点过大.
GPTQ
经典之作, 目前几乎是4bit/3bit方案的默认首选, 但也仅限于开源世界的娱乐可用, 离落地认定的靠谱精度还是有比较大的距离. 该方法来源于同一团队在nips22的工作(Optimal Brain Compression)延伸, 其同样将方法泛化到剪枝领域(也是大模型剪枝领域的经典, SparseGPT). 该方法的思路大致为: 利用hessian信息作为准则判定每个权重量化后对输出loss(通常定义为MSE)造成的影响, 量化影响最大的权重(即最敏感)挑选出来先进行量化, 然后对其他权重进行更新来补偿该权重量化导致的影响, 如此往复, 直至全部量化结果. 当然, 在GPTQ中作了一些简化, 比如是基于列元素进行量化循环, 来减少算法的运行时间. 该方法的优点: 首次将4bit/3bit权重量化在176B的模型上做work, 同时也提出对应的kernel(但比较糙, 优化空间大, 有不少团队做了优化). 缺点: 4bit/3bit的方案原始kernel由于有unpack操作, 导致gemv操作的计算时间低于fp16), 且精度距离落地有明显距离. 注: 从它开始, 很多人只开始研究4w16f的方案(即weight-only quantization), 因为在batch=1的gemv计算中, 只需要控制权重的读入时间即可, 且input的动态范围过大, 量化掉点过大.
AWQ, Activation-aware Weight Quantization
SmoothQuant的续作, 从源代码来看, 它对SmoothQuant中计算scale时需要的超参alpha, 增加 了一步通过grid search得到每个scale的最优参数, 但论文的故事包装得很好, 同时取得的效果也是十分显著的, 符合大道至简的准则. 该方案是也是4-bit weight-only quantization, 其kernel实现凭借对PTX的深刻理解和应用, 取得了目前这些weight-only quantization的方案的第一. 在此基础上稍加优化即可以得到一个不错的baseline.
SqueezeLLM
通过观察到部分权重决定了最终模型的量化性能, 提出以非均匀量化的方式缩小这些敏感权重的量化误差. 即通过loss的二阶hessian信息来确定量化敏感的权重, 将量化点安置在这些敏感权重附近, 其它点以MSE最小来安置. 该方法以少量的存储空间换来了目前最优的4-bit weight精度, 但其缺点也是极其明显: 由于采用LUT来实现非均匀量化, 导致其kernel在batch > 1(文中的batch我均定义为 batch * seqlen)的情况下, Linear的执行速度急剧下滑。
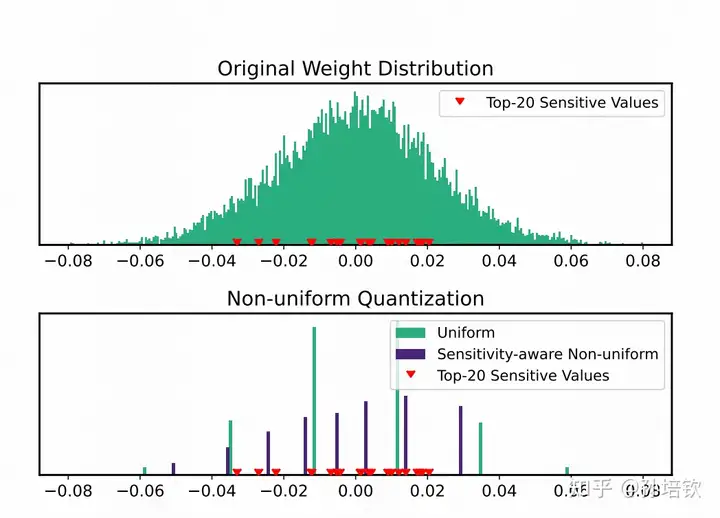
QLoRA
这里顺带简单介绍一下QLoRA. 该方法提出4-bit NormalFloat, 一种新的数制(属于非均匀量化), 从理论角度上证明是4bit最优数制。 利用该方法量化模型的backbone得到4-bit的backbone, 然后基于lora进行SFT, 在只需要4-bit模型权重的情况下完成SFT, 从而使得许多人可以实现在单张消费级卡(i.e. 3080)上玩LLaMA。但当时我跑它的时候, 其缺点就是明显的kernel速度慢, 原因同样是因为它需要通过LUT来实现, 不知道现在情况怎么样了.
Summary & Future
个人认为, 4-bit weight-only quantization是一个相对比较均衡的方案。 在这个setting下, 量化的研究工作应更多集中在模型的精度提升的层面上, 尽可能地减少对模型智能的影响. 但对于如果想进一步得到更轻更快更强的模型, 可以从其他小型化策略入手. 在这些策略中, 个人认为蒸馏是一个最值得往前走的方案. 在LLaMA-2的tecnical report中就有多处地方使用了蒸馏, 比如: 在RLHF阶段仅用70B的reject sampling dataset来fine-tuning其他几个小尺寸的模型, 以及很多人都会尝试去用GPT4的SFT数据来fine-tuning自己的模型. 剪枝不太推荐, 因为至少从SparseGPT的复现结果来看, 除了非结构化剪枝精度还算有保证外, 其余方案精度下滑明显, 包括NV的2:4和4:8方案, 距离落地还有些距离, 且和量化结合后并不能进一步拿到50%的压缩收益。最后, 再提几点我认为有可能可以做的方向吧:
- 更加系统全面地推理优化,包括: 更深度更大粒度的kernel-fusion, 其他部件优化(i.e. long context 下kv-cache的存储和IO时间, attention计算优化), system2的推理路径的优化
- 在模型训练中引入量化友好的策略, 来使得模型的权重和激活可以变得对量化不敏感, 从而实现4w4f
- 尝试引入QAT方案, 达到所见即所得, 拥抱极限 — 但这个有点太激进, 还是需要在模型有足够理解后去尝试.
- 端云推理的协同优化, 即手机端和GPU之间如何交互, 利用手机端训个人SFT, 分配算力等